So I have personally begun the dive into Machine Learning (ML) with Terminal. It is my opinion that this strategy has taken a back seat since these discussions:
Machine Learning
How does the machine learning portion come into play?
Machine learning libraries
It is my goal with this topic to revamp some of the interest and discussion around ML. Personally, I hope to make ML a valid and viable option that can be successful in the competition.
I’ll begin by discussing a little bit about what I’ve done so far and what I plan to do, and hope other people will share their attempts as well.
My Current Setup:
Currently, I am only using ML for building defenses. I believe I can train a separate network to process attack strategies, but I want to work out what are viable network settings first.
I have started by running a very basic Keras neural network. It accepts the map positions in vector format as well as information about each players health, bits, and cores as inputs. It has several layers scaling up to my desired output vector shape. Essentially, I am running a multi-class classification network where I determine whether each map position should be filled, and with what (static) unit. The difficulty of using Keras is that we cannot use it in the Terminal space. So I save all of the weights from the trained model in JSON format. Then, I created my own .pyd or .so binary file from C code to handle matrix and vector operations. I then only need to load the weights at the beginning setup time and then just run forward propagation every turn.
For those interested, if you manually do forward propagation I believe writing your own binary is well worth it since my algo runs with approximately 60ms per turn with a 5 layer network. I did some tests before I started and these are some results for matrix multiplication (keep in mind this is still highly inefficient C code and my computer is also quite slow since I was using a laptop  , also that for the network it is matrix-vector multiplication, which is also much faster):
, also that for the network it is matrix-vector multiplication, which is also much faster):
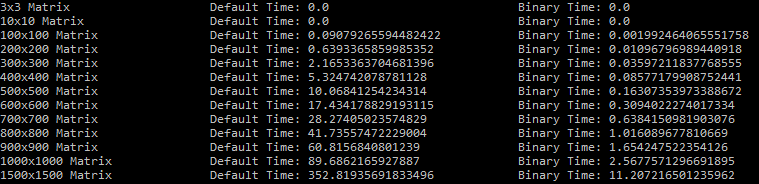
The default time is using raw python with list comprehension, binary time is using my .pyd (or .so) file.
In this current state, I don’t expect this algo (regardless of how I train the network) to do very well because it is only capable of copying or imitating already existing strategies. Its possible advantage is that when trained on lots of different matches/algos it will apply these different strategies based on the situation. This copying effect becomes apparent when training on a single algo.
As a test case (to make sure it was doing what I expected), I trained a network on 99 matches (or 2258 turns) from the algo KeKroepes_3.27 made by @kkroep. If the network works as expected, after training, every match it played its defense would build to match KeKroepes_3.27. Sure enough, after uploading this algo I found it more or less was getting close. Here is an example match where you can see it sort of matches the actual design. Ignore the attack, since that is just a placeholder for now.
Hence the click-bait name of this topic  , I believe if you exclusively trained a network on a single algo’s defense and attack, you could very effectively copy that algo without any hard code, which is an interesting thought. I wouldn’t be too worried about this strategy, however, since I doubt many people will be making ML models to do this and it also will doubtless not work as reliably as a hard-coded algo - but this is still interesting.
, I believe if you exclusively trained a network on a single algo’s defense and attack, you could very effectively copy that algo without any hard code, which is an interesting thought. I wouldn’t be too worried about this strategy, however, since I doubt many people will be making ML models to do this and it also will doubtless not work as reliably as a hard-coded algo - but this is still interesting.
After my little test (thank you @kkroep  ) I then trained a network on ~11,000 matches (or 319,600 turns) for an extremely short period (only like 10 epochs) just to see what it would spit out. As expected (from the short training time), it was never very confident (confident predictions were typically below .3) but I uploaded it just to see what would happen. Most of the time it loses because it almost always blocks everything, something I believe is caused by its low confidence (eg training time) and thus inability to choose 1 strategy. Thus it tries to follow several and ends up just filling basically everything. However, this match gives me hope that it could learn to actually learn and follow different strategies.
) I then trained a network on ~11,000 matches (or 319,600 turns) for an extremely short period (only like 10 epochs) just to see what it would spit out. As expected (from the short training time), it was never very confident (confident predictions were typically below .3) but I uploaded it just to see what would happen. Most of the time it loses because it almost always blocks everything, something I believe is caused by its low confidence (eg training time) and thus inability to choose 1 strategy. Thus it tries to follow several and ends up just filling basically everything. However, this match gives me hope that it could learn to actually learn and follow different strategies.
Keep in mind that for all of the matches I have posted from my own algos, I have zero hard-coded information on how to build defenses (as I said, attack is hard-coded and a placeholder). Everything is 100% determined by a ML network.
(In all the matches, my algos are the ones that start with dumb-dumb-ML)
My Plans:
I want to continue to see for a little while if the above approach (copy-cat) can be viable (I am currently training a second version of the 11,000 matches where I fully train it). Viable meaning it can actually commit to and win some matches using a recognizable strategy.
However, I believe this type of learning will always be a little bit behind and not as interesting because it does not actually develop anything new. It will always be limited to understanding matches that have already been played.
Thus, I am very interested in implementing a NEAT approach to this design. In other words, train like I would above, but then run a NEAT algorithm to have it continue to learn dynamically. Or maybe NEAT right away, but this has already been discussed in the topics linked above about the issues regarding training time.
What are other people’s thoughts? Has anyone successfully trained and implemented an algo using ML? What types of networks have people tried? What suggestions do people have for things I could try?
Throw everything out there :).
 ) but I am not sure I will be able to do that before the end of december. (I just finished a very fast and almost perfect simulator so I have to make some use of it
) but I am not sure I will be able to do that before the end of december. (I just finished a very fast and almost perfect simulator so I have to make some use of it  )
) . In all seriousness though, awesome post, and good job! I will have to say though, that you picked a very unfortunate algorithm to learn from if you only use firewall placement. The design philosophy behind my algorithms focusses on effective attacking, rather than effective defending. The firewall structure has this specific shape to allow for small changes to result in very different attacks. If you look at the replay you provided of my algo, you’ll see that almost every attack is very effective.
. In all seriousness though, awesome post, and good job! I will have to say though, that you picked a very unfortunate algorithm to learn from if you only use firewall placement. The design philosophy behind my algorithms focusses on effective attacking, rather than effective defending. The firewall structure has this specific shape to allow for small changes to result in very different attacks. If you look at the replay you provided of my algo, you’ll see that almost every attack is very effective.

 .
. )
)
 .
.