So I’m sure some people are curious how a row-3 EMP line was able to be successful (or perhaps those curious already figured it out). But I haven’t seen a lot of discussion on the forums regarding what especially fuels my algo. I’m think most people incorporated this in some way (I believe several top players referenced using simulations to make their predictions), but here’s my breakdown on one of the most important parts of an algo.
Theory
As mentioned in the machine learning posts, a unique game aspect of Terminal is not knowing the enemy’s placements for a given turn. This makes the information one received slightly incomplete, as the game state string passed to an algo is only as recent as the Restore Phase of the turn, making it (essentially) one turn behind.
A large part of an algo’s ability to make meaningful choices is its knowledge of the enemy’s next turn. A simple example of this is breaking through a maze algo’s filter line. Without predicting its next placements, an algo might simulate going through that hole again and send an attack that gets stopped by the maze filling in the gap that was opened. Closing the gap between one turn behind to zero turns behind enables intelligent placements. Having a perfect predictor is not necessarily possible, but approaching it (especially against static algos) is certainly possible.
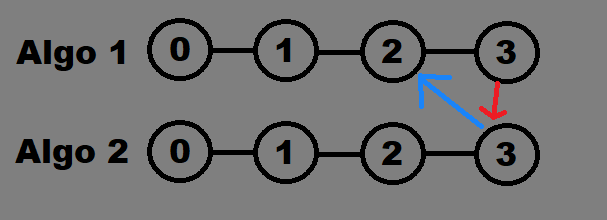
(Note, these graphics only get worse and are indeed MS Paint. This is supposed to represent a game on turn 3 where on algo sees its opponent as of turn 2, while the other predicted to see its opponent as of turn 3.)
Implementation Overview
My teammate, @rogerhh, was the mastermind behind our prediction phases’ implementation, so he’s more than welcome to respond with further implementation details, but I’ll provide a high level overview of how we predicted enemy algos.
The prediction logic was primarily two-fold: knowledge and learning. Each component of the prediction phase (which we called predictors) represented a generic behavior of algos. Some of these are generic to all algos, which we gave as knowledge to the prediction phase (and are always employed), but most are unique patterns of behavior found in only some algos. This spawned a small army of predictors that enable the algo to learn about its enemy as the game goes on. We’ll call this a primitive form of machine learning (in the sense of game output driving program logic, not the sense that we know what we’re doing). As each predictor makes a prediction about the enemy’s next placements, correct predictions reward confidence. Confident predictors are employed by the prediction phase to spend the enemy’s cores and bits for them, handing over an already-placed game state to the regular logic of the algo.
Results
We had massive success with our prediction phase. We never really tracked the accuracy of our predictions (we were more concerned about debugging the predictors than seeing how close to zero turns behind we got), so we don’t have many nerd stats to share. However, the results speak well for themselves, especially considering the bad strategy I was using that was propped up on our ability to predict.
-
Simulations: Predictions enable for less simulations to be used. Until the last 3 days, we only ran 20-30 simulations per turn (40-50 now since we had computation time to burn). Running more than that wasn’t necessary as we already had a good idea of what our opponent’s side of the board would look like. Some secret-sauce and a few dedicated optimizers enabled the coordination of defensive placements with offensive placements, so we only ran 2-4 EMP simulations, 16 ping simulations, and 4 scrambler simulations (later 2-8, 20, and 20 when we upped it). In comparison to using 50,000 simulations per turn, I’d say this turned out well.
-
Emergent Behavior: Predictions enable several emergent behaviors of our algo. One example is sometimes the algo will see the breakthrough of our EMP line coming and it’ll simulate something like scramblers stopping the attack and catching the opponent off-guard by using the new hole as an exit that turn. Combined with poor defensive placement logic, this also enables that exit to be used (or not used) the next turn, often catching more adaptive algos off-guard as they will either predict (or not predict) the hole being filled, and we may do the opposite if it simulated in the algo’s favor.
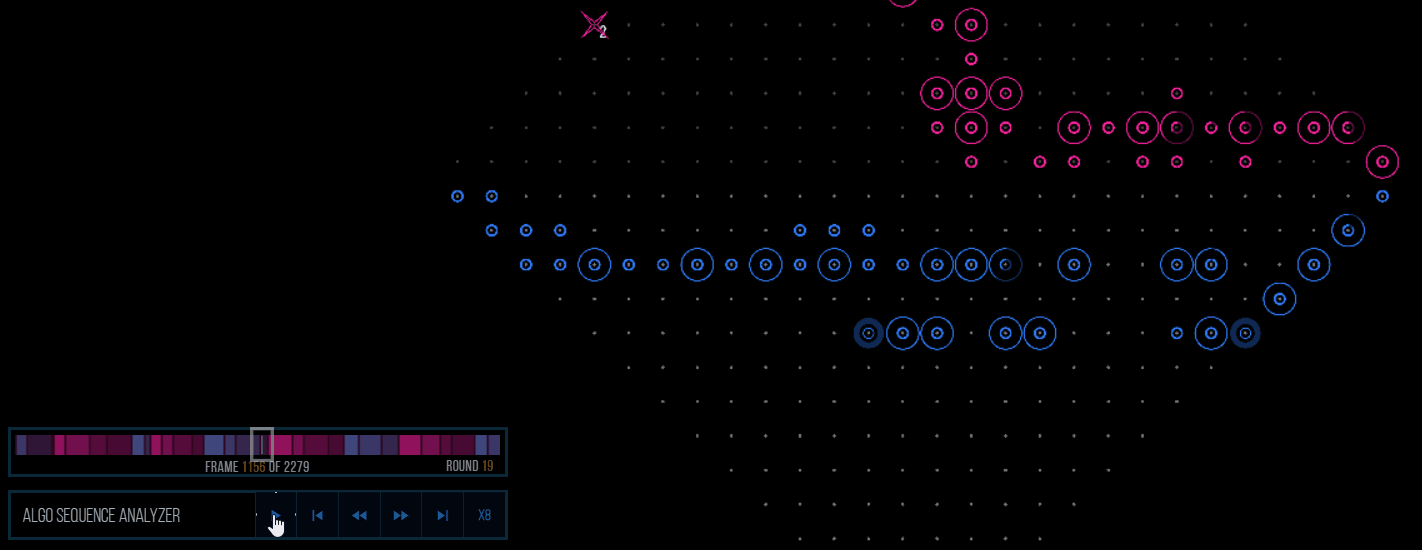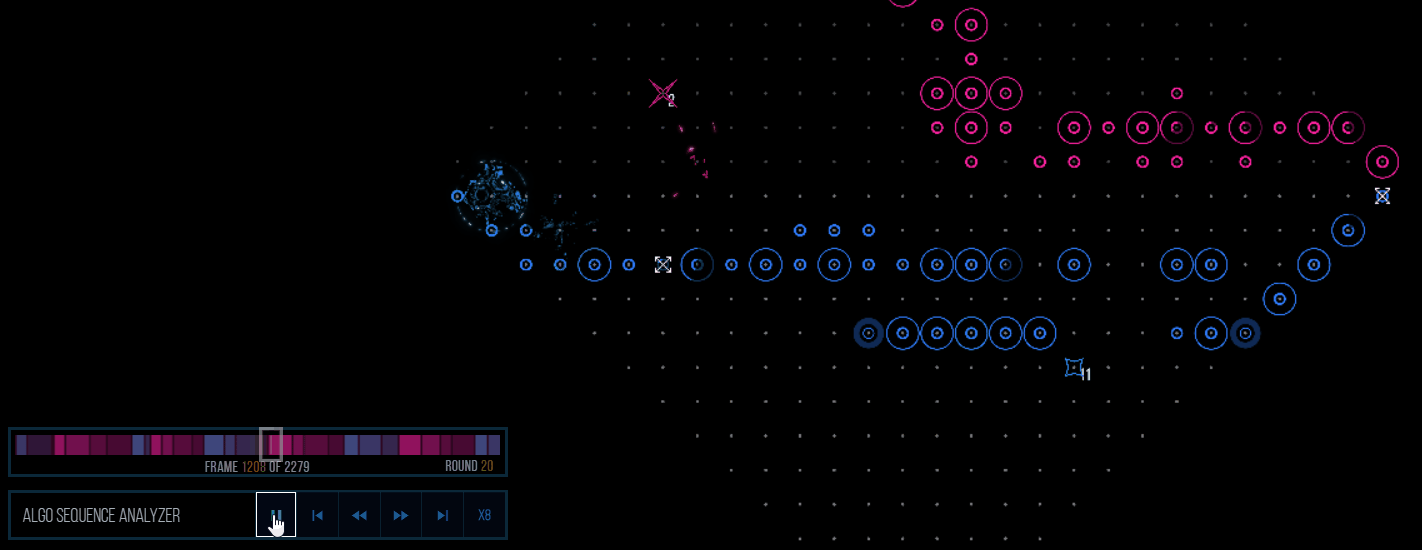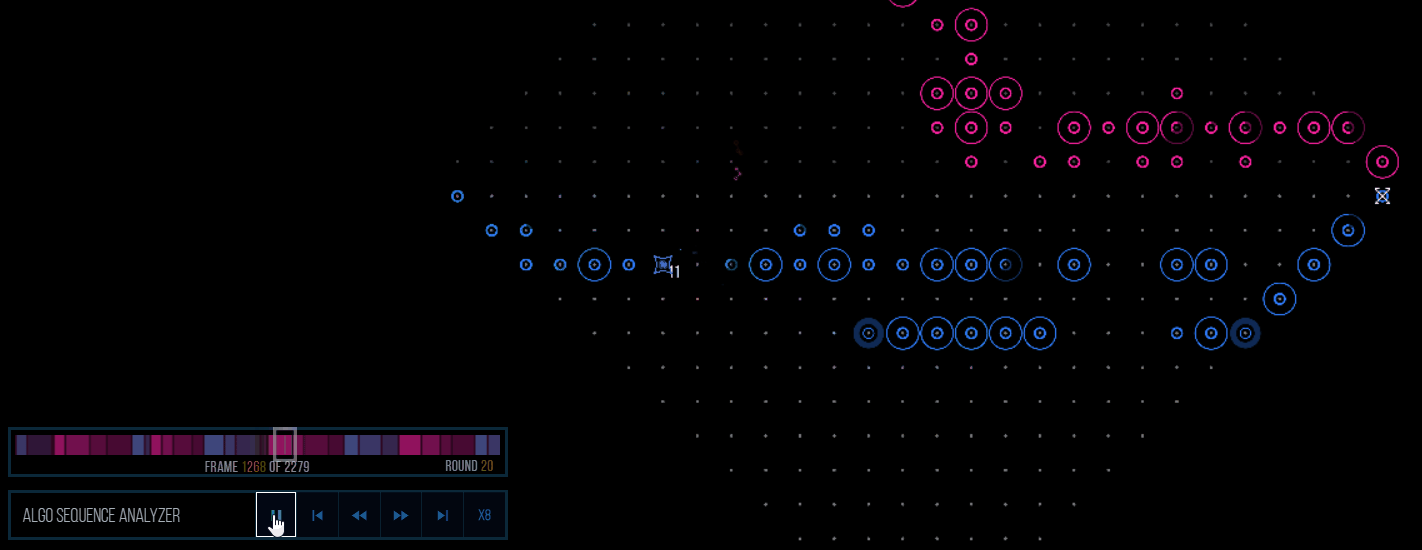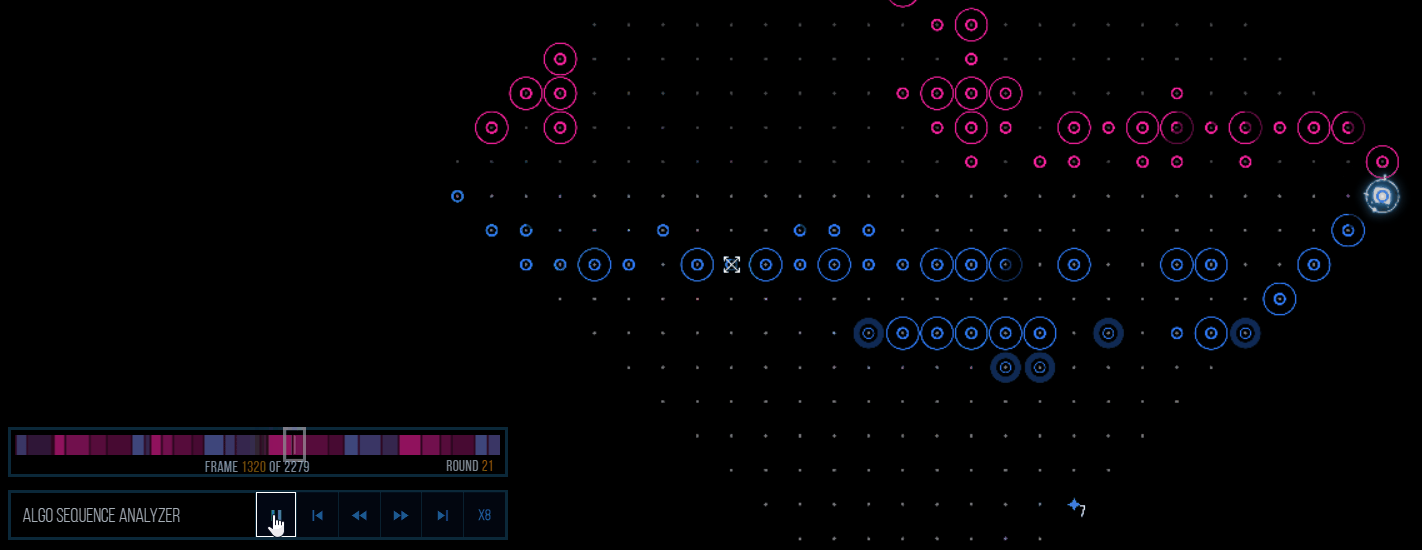
(This is versus AELGOO54. A same-turn exit allows for 11 scramblers to score, as well as AELGOO over-investing into defenses that can later be destroyed with EMPs.)Another is that the predictions enabled us to define our metrics (which compare the outcome of each simulation) to use some obnoxious behavior, like stopping 20 pings with scramblers or generally stopping every attack our opponent sends out. This behavior isn’t explicitly defined which makes it all the more enjoyable to see happen. Of course, inaccurate predictions will make these defensive-based attacks fall flat on their face (see round 69) since they usually carry little benefit on their own, but it’s generally a positive aspect of the algo.
-
Structure: We never moved away from a row-3 EMP line (in favor of the more carefully designed structures like mazes, demuxes, or row 1/2 battle-to-the-death whatever those are). I theorize that having a consistent base structure that funnels all units through a defined “exit” helps make accurate predictions by “stabilizing” the enemy’s behavior, but overall I think having success with this kind of structure speaks well for using predictions to empower an algo’s behavior.
Future of Predictors
I’m curious to see where this will go. I’m not exactly sure to what degree other players have been doing this since it’s been primarily absent from the forums, but I think in the future we could even start to see some mind games with “to do or not to do, to predict or not to predict” (explicit logic of the emergent behaviors I mentioned would be an example) and really get into the 4th dimensional chess strategies this game is capable of. I also think it could help machine-learning approaches if they were supplemented with an intelligent predictor to assist with knowledge of the game state, or perhaps someone will use machine-learning to make an intelligent predictor.
- I used a prediction phase
- I used simulations to make predictions
- I did not use a prediction phase
- Other
0 voters


