Below, I prepared a list of matches of the top five algos on the current leader board and added information about their enemy’s elo score.
There are quite a few observations we can make here:
All of the top algos are matched up against significantly worse opponents (I will come to the reasons later).
The higher their elo the lower their enemies’ elo (almost).
While we already observed that there are no matches against equally strong algos, we can also see that they are sometimes facing horrible algos, which probably just crash and therefore have a negative score.
Explanation
The fact that the strongest opponent had 1702 elo, which is still not matching them (algos with more than 1702 might be near a hundred because many of the top users have multiple algos in that region), is explained by two major attributes of the matchmaking:
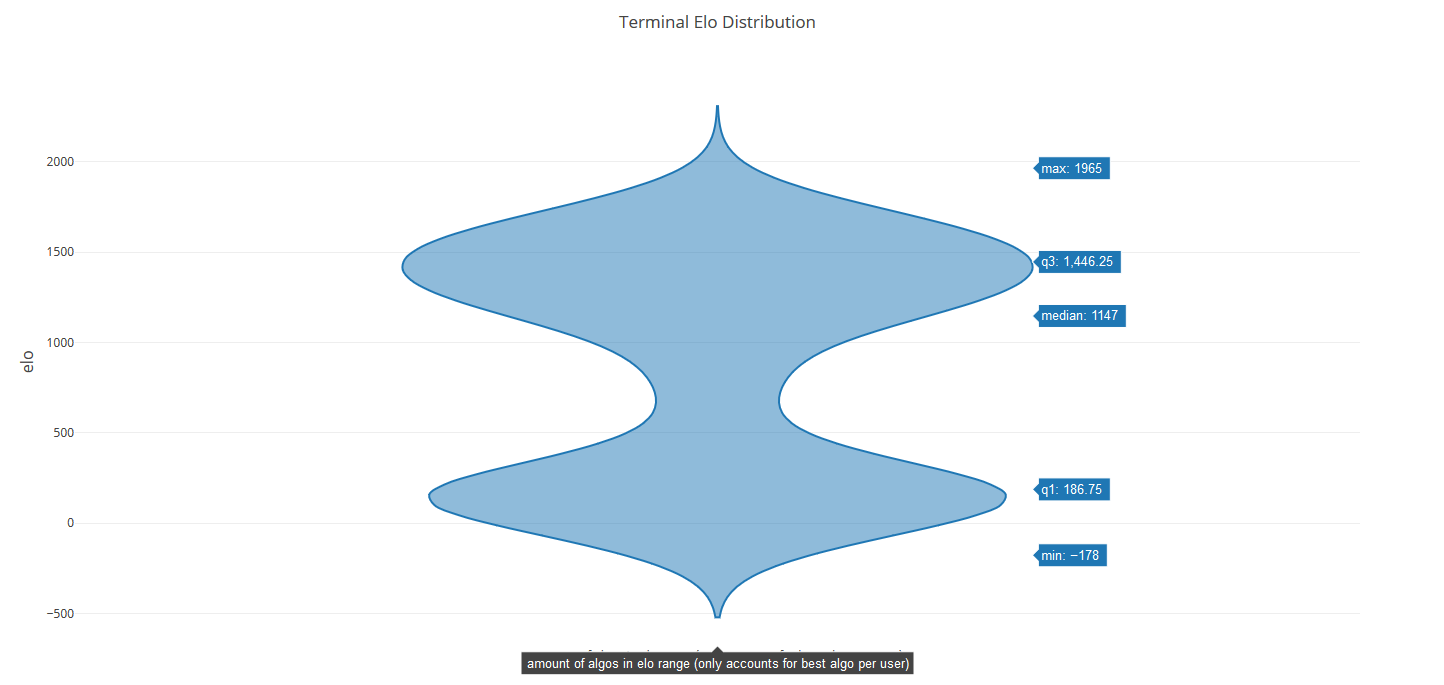
First of all, there are no rematches possible, which explains why Truth_of_Cthaeh is facing the worst enemies: It is the oldest algo and has probably already played most of the high elo competitors. Secondly, I have graphed the distribution of best algos for each user on the leader board for you:
The reason why it looks like there are algos above 2000 and below -500 is due to the nature of the plot I have chosen.
The graph allows us to make out two important features of the elo distribution:
The median lies at 1147.
There are two big bumps: One a bit below the starter elo (1500) and one at 186.75.
The lower “bump” probably consists of crashing algos and thus might move down even further with time if they keep receiving this amount of matches.
Coming back to Cthaeh's matches: Due to the distribution of algos in Terminal, the likelihood of the top algos matching against lower tier algos is very high because every algo appears to be having the same amount of matches.
Because sawtooth and rank three to five are “younger” than our top algo, they can still match against higher tier algos that KauffK’s algo might have already beaten.
Combining the fact that the majority of algos are ranked way below 1702 elo and that the top algos have already faced some of the other top algos, it is just very unlikely that they are going to play against equally strong opponents if every algo has an equal probability of playing (which is why I proposed this idea).
Acknowledging this, we can easily understand that the top algos will not lose against (often crashing) way worse algos and thus stay where they are at.
The number after each of the top five’s names is their elo and the one below each title (~{number}) represents the average elo of their enemies and the score of each algo they were facing is displayed right next to the watch link. All losses from the respective algos are marked bold + italic and feature the name of the algo that managed to beat them.
The title is referring to the current matchmaking situation and “Any Time Soon” is short term compared to the existence of Terminal => days/weeks.
I agree sth needs to be changed. For example i don’t understand why top algo is mached with low elo algos when there are higher placed algos that didn’t play vs the top one yet.
For example i uploaded my algo 2 days ago, it’s doing well and is curently 1700 elo +, yet it didn’t get a chance to play vs the top algos while they are playing vs algos below 1500 elo.
Great analysis. Wanted to ask about graph and above 2000, but you already covered it.
I support this idea.
This will not affect the tournament results, however, would be nice to see matchmaking according to strength of algorithm rather than giving false impression for ones on the top. As @876584635678890 has shown top algos unfortunately are faced against weaker algos and could be surprised to see the tournament results.
@ziomkus For other anecdotal evidence, I have an algo on the rise that was added a couple days ago (currently sitting at 1751 elo).
In the last 18 matches I can see currently (the list shown in MyAlgos), I’ve played two algos of note - one at 1842 and one at 1833. But I also see 5 matches against algos under 300.
I saw one reference to algos needing to be marked as “available”, so maybe the mass of low tier algos is locking up competent opponents?
Maybe this all gets solved once the “fix” to only match algos within 400 of each other goes in?
Edit: given @Janis’s point, with the CodeBullet competition in one week, I’m eager for real feedback on my algo. I really hope the change to match making can be made with enough time to be meaningful for all of us.
@Janis It will indeed only affect results of the global competition, but that it could potentially be inaccurate due to unlucky matchmaking, which makes it harder to improve on algos.
I changed the link to the graph to now show a histogram by default, which will just give you a different view on the data, which is less misleading, but also does not show the distribution as uniformly.
@n-sanders My personal experience has also shown that feedback is slow.
This is especially unfortunate because manual algos (contrary to e.g. machine learning) do not take a lot of time to adjust and therefore decisions could be based on false perception of how your algos performed.
@876584635678890 Did you pull elo numbers from crawling api/game/leaderboard?page=X ?
I trust the accuracy of the trend, but it’s worth being a little cautious with some specifics. The leaderboard (as of a couple weeks ago) only includes the highest elo for each user. I’m guessing KauffK has 6 Truth_of_Cthaeh uploaded (and apparently all named the same!) and all probably with 1800+ elo. That may even affect the median calculation (assuming the users who uploaded crashbots haven’t uploaded any new algos given their best performing is still a crash bot).
I’m not disagreeing at all with your findings - match making needs to be fixed, just wanted to give that word of caution as people look over this data.
The algos should be closer to a normal distribution on the leaderboard, but the large lump at the bottom is due partly to an issue that existed last week and fixed on monday where losers were losing more points than intended.
We have 3 ‘low hanging fruit’ updates in the works for matchmaking which we are hoping to deploy by the end of next week, and should help a lot with the existing issues in matchmaking. You can check those out on the other post discussing matchmaking.
Probably a long shot, but would lowering the scope of the (initial) matchmaking fix give you a chance to deploy it before the CodeBullet challenge? Even if just #1 was done (avoid matchmaking when 0 Elo can be gained) it would do wonders for getting real, meaningful feedback in time for that major event.
Out of curiosity, and not really related to this thread but it sparked my question when I read how the leaderboard should ideally be useful feedback for competitions:
How are competition winners determined? Presumably not ELO because that doesn’t seem quite right. But I would expect that the competition match process accounts for the non-transitive victory relationship between many algos. Round-Robin scoring or something like that?
Really? I will be surprised and concerned if that is true. Leaderboard has shown many cases of algos that beat most opponents, but lose to a few that for whatever reason have a design that counters them specifically but loses to most others. (Take for example this now-famous occurance: Match of the Week)
If I just happened to be paired with one such algo in the first bracket of a single-elimination tournament, I would be pretty upset and I imagine others would be as well.
@KauffK I covered the order of events of that competition in more detail here.
From that you can make out that the highest elo algo was able to win the tournament, but I feel like these concerns would be valid and that raises a bunch of problems in my mind, I will not write out loud here.
However, you need to remember that that is kinda the point of a tournament and I am totally fine with.
If your algo is not perfect, it might be “unlucky” and lose to another algo that counters it, but that is the strength of that algo and it was unarguably stronger in at least that aspect.
You’re right single elimination has a lot of issues and are a little luck based (though if your algo is perfect you don’t need luck as 8 said).
Some solutions we are already implementing. One is seeding based on ELO so that if you are high ELO you’re more likely to be matched with low ELO algos in the beginning, and it awards posting your algo earlier instead of keeping it a secret. So if you worked hard on your algo you should have a good chance of making it past the initial rounds at least.
Another is we plan on having frequent tournaments. So that even if you get some bad luck in one tournament you can enter another in a week or two.
In general the tournaments are more for “hype”, fun, and introducing people to the game, and we wanted to keep them simple. While the ELO system is meant to be more for figuring out who is truly the best.
Lastly, the big prize money for the global competition is based on ELO so you don’t have to worry about unlucky matches for that.
But we are still discussing all of this internally, though big changes to the tournaments are possible we may have other cooler features to prioritize.
@C1Junaid Just wanted to mention that I can cosign all of what you said and that seeding is a really nice idea, which embraces the idea of tournaments even more
@KauffK@8
To add to these points, we are still very early on in terminals lifecycle. We have almost exclusively discussed plans that we plan to implement in the very most 3 weeks, but once all of our core features are fully fleshed out we will definitely be experimenting with different formats for tournaments.
@n-sanders
I can confirm that there is an extremely low chance that matchmaking changes will be made before the codebullet challenge. We have a live event at UMich next weekend, and for business reasons features related to that event have been prioritized. This includes a learning center for better on boarding, and things relating exclusively to our live-events.
The ‘cop out’ I can give you is that everyone is equally disadvantaged by the current issues with matchmaking, though its obviously not ideal for anyone.
@RegularRyan
Thanks for your transparency. The root cause here is how much I’m enjoying this whole thing.
I had originally planned to just participate in the CodeBullet competition and wind down my involvement after that, but now that I’m so close to cracking the top 10 global leader board, there’s no way I’d be content to stop in a week!
I’m excited to see what’s more to come as things continue to evolve here

 as 8 said).
as 8 said).

