I want to try to incorporate the impact on pathing of tower placements when evaluating where to place a new tower. But, the default pathing methods in Navigation.py are too slow to search more than a few 10s of paths and arrangements.
First off, if anyone else is working on this, I was able to speed up the default methods by around 6-7x just by optimizing the existing code (e.g. https://wiki.python.org/moin/PythonSpeed/PerformanceTips) particularly, replacing the queue.Queue with a simple list makes a huge difference and also only looking at paths that reach the opposing edge (ignoring cases where the information would self-destruct) can cut out a lot of the work that needs to be done. But these are only improvements on the existing algorithm.
Has anyone spent much time on finding a faster algorithm? It seems that it should be possible to use some kind of A* search to find the correct path far faster than the default breadth-first, but differing targets when they are blocked and the preference to zig-zag seems to throw a wrench into this plan. Particularly the zig-zagging makes the path “stateful”, which is a huge pain.
I haven’t done much with this since optimization isn’t really a priority right now, but I have thought about it a little bit. First, I haven’t looked much at how the algorithm works right now, but typically a good place to start is the loops. Anywhere you can replace searching through loops will work way faster with hashing. What I have done is convert most of the program to use tuples instead of lists, which then means I can search python dicts with O(1) instead of O(n). This could possibly have a large effect for navigation if you are searching every single time you check the location, etc (again, haven’t looked at the actual algorithm yet, but this is a common thing for pathfinding algorithms).
Another thing to keep in mind is that maybe you can simpify the algorithm to be much faster, but not work in special cases. As long as you are aware of those special cases, recognize, and account for them you can usually make much simpler versions of algorithms that aren’t perfect. A good example of this is the travelling salesman problem, where a real solution has not been found, but many imperfect algorithms have that can work much faster.
Just quickly noting that we intentionally made the pathing in starter-algo super inefficient and leave it as a challenge for our players to replace it. The pathing we use in engine is my pride and joy though, I actually wrote a blog post about it on my personal site.
https://www.ryanmcpartlan.com/pathfinding/
There are a few sentances that need editting and i’m pretty unhappy with the layout (I’m mostly backend so I pulled it off wordpress), but the content might be helpful for players working on custom pathfinding algorithms.
I personally replaced the default pathfinder with a variation of Dijkstra’s algorithm.
I use it this algorithm in an attack simulation method that can predict with a good precision the result of an action phase where every units would be of the same type and start at the same location.
I run about 150 of these simulations per turn, each one calling my Dijkstra algorithm several time (because of firewalls being destructed).
I however think I could greatly improve my algo if I found a smart way to reuse the precedents pathfinding, since they use identical or very similar maps, with just the starting locations being different.
That sounds great @Aeldrexan! It is good to see someone has successfully looked at this problem. Do you have a good way to determine each unit’s end point? When I first wrote this post this seemed to me like a major problem because you had to do a search to determine first where the unit’s endpoint was. However, for a fixed starting edge, I now think I see that each tile should have a unique goal-point where any information starting on that tile will path to right? So, each region of the board will have, for each starting edge, a unique goal point to which you can compute the distances. To deal with the zig-zagging the future path is still dependent on where it came from, but that isn’t a problem when labeling destinations and distances.
My understanding is that this is partially true. To quote the documentation:
When it is time for a Unit to choose a tile to step onto
Choose the tile which is the shortest number of steps from the Unit’s destination, described below.
…
Where the other steps are just to deal with the exceptions of ties, etc. But the main determiner for end goal is clear, the shortest path to the destination, which is defined as:
A Units destination is usually the opposite edge of the edge it was created on.
Because the target is an edge, not a point, this destination can change as the match goes on either from firewall creation or destruction. This leads to the doubling back behavior we sometimes see as well. However, in many turns, there is no change in either of these. What I personally will probably do is check whether the map has changed (firewalls only) and only recalculate targets then. You can do additional pruning by checking to see if the unit is passed the changed point, etc. I’ll leave further steps to the reader :).
One question I have is whether or not this distance is measured by steps or by Euclidean distance. If Euclidean, this becomes almost trivial, if not, then less so.
EDIT: Just re-read my post realizing I answer this question myself from the quote I posted, it is measured in steps.
Indeed, but the difficulty is in determining the destination. It requires first checking if a path to the opposite edge is available, if so, that is the destination; if not, you need to find the deepest reachable location on the opponent’s side of the map. If you can know a-priori what the destination is, then it is easy to find a shortest path.
I earlier thought that finding the destination required doing a depth-first search of the map for every path you want to look at, but I now think the destinations can actually be computed once and cached for each map tile. I believe this is what @RegularRyan’s blog is referring to as a pocket, as well as a comment in the Navigation.py code. Each reachable ideal endpoint defines a pocket of the map to which tiles belong, and critically, each tile belongs to a unique pocket.
Addendum: I should say that each tile belongs to a unique pocket, for a fixed goal edge. Each goal edge requires looking at a separate copy of the map.
Part way through writing this I realized you were talking about caching for individual unit pathing based on the same map. I had originally interpreted caching as talking about different map states. Posting it anyway since I am interested in peoples thoughts :).
I agree, you can cache once and use the same initial condition search for each iteration you run. However, the instant something is destroyed/created in a frame, it must (theoretically - you could decide what is necessary) be completely recalculated. This is obviously sub-optimal, here are a few thoughts.
First, what I briefly mentioned above. Decide what points need to be calculated. This requires already having a pretty concrete idea of where you will spawn your next units, so I consider this to be less helpful since you really want to have the path information worked out before you decide where to spawn so you can use it to determine your spawn location. Thus, I don’t really consider this a valid option.
Second, how useful is caching the map? I would argue not very (with absolutely no evidence) for the single reason that it is not a static map (edit: it obviously is worth it when analyzing the same map for different units). The map can and does change quite frequently. That being said, I do think caching is a good idea to reduce calculations when nothing changes. But for the sake of the algorithm and more importantly, virtual maps, I do not think caching the map for the game state on the start of the turn is enough, because you have to re-cache it for virtually every scenario you would be interested in recreating. Predicting where to spawn attack units? Re-cache for destroyed units. Predicting where to spawn firewalls? Re-cache for each time you try adding a new unit.
I’m not 100% sure of a solution for this right now, but I want to think about it and hear other people’s thoughts as well since it would be nice to have an efficient way to re-calculate a new map based upon an old one. What first comes to mind is deriving new cached values based on the previous one, provided there is only a single change. Then, you could iterate this step to have a valid map without having to do a complete recalculation. Just a thought .
The unit don’t have a goal-point, the complete edge is it’s target. So I don’t need to determine the end point in a first step, I directly apply the Dijkstra’s algorithm.
I update a ‘best_location_for_self_destruction’ in the main loop of the Dijkstra’s algorithm in case it don’t reach the edge.
I implement the zig-zag preference by adding the tiles in the correct order in the queue (or list)
I believe the unit does have a set, single target point, which is determined based upon step distance to the edge. Dijkstra’s algorithm merely takes this into account for determining the best path to an edge, since that point will naturally always be the shortest, which is the rule the engine uses for choosing the units path. So this is a trivial difference, just thought I’d point it out since it could change the algorithm one uses to calculate an individual units path with an un-cached map. Dijkstra’s is an excellent one for caching an entire map though.
I was excited to see this and have been waiting to find you in the top 10. Looks like it didn’t take too long.
Just had a laugh watching our algos fight, clearly we’re both up to some shenanigans with dynamic targeting and it looks like you’ve taken a crack at dynamic base building as well, but against each other they nearly killed themselves just by thinking too hard https://terminal.c1games.com/watch/555123
Lol, I think that what happened in that game was that the server running our algos was just slow. We should both consider that case for our future versions
I have tried recreating the pathfinding from scratch using A* and got pretty good results.
I don’t want to tell too much about the details but I can tell so much that you can precalculate the direction a unit has to go based on if the last direction the unit moved was vertical or horizontal and what edge it targets.
You can keep this precalculation as long as no stationary unit gets added to or removed from the board.
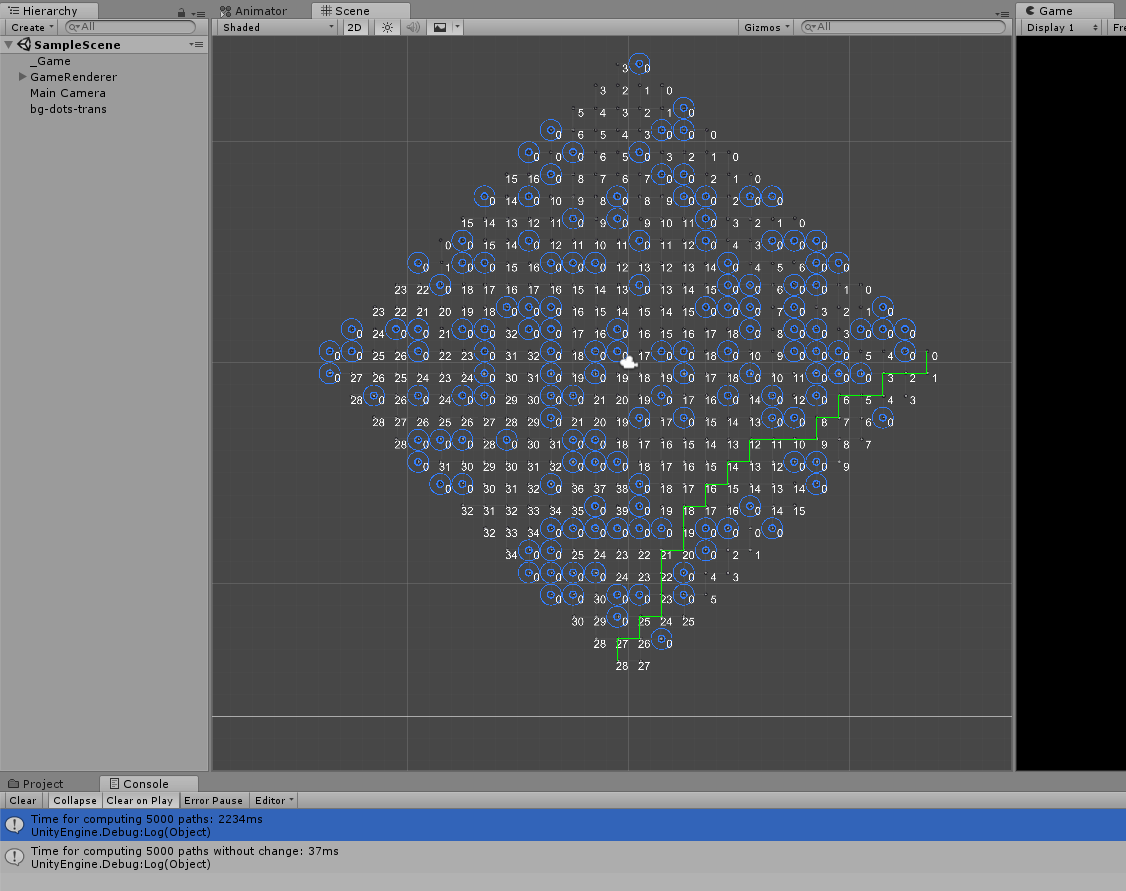
The A* pathfinding is used to give every location on the board a value for the distance to the best destination as seen in the image.
After this, every location gets 2 directions (1 for entering it vertically and 1 for entering it horizontally), which direction is chosen is based on the pathing logic (https://terminal.c1games.com/rules#UnitMovement)
With this information, you can now calculate any path for the current game state by following the given directions.
The results speak for themselves:
2000-2600 ms for 5000 paths (changing the board in between, details below)
2-40 ms for 5000 paths (without changing the board)
For the test with varying boards, I added 1 Destructor on a random location and tried to remove 3 units at 3 random locations on the board everytime a path was calculated (starting with a clear board).
The second test then used the last board and calculated a path 5000 times.
The start location for the pathfinding was always [13, 0] and my computer runs at a speed of 2.8 GHz
Keep in mind though that I programmed this in C# and the results could be different in python.
I did a few more things than I mentioned above but I don’t want to make it too easy to get a good pathfinding algorithm.
Just an update on my pathfinding method for Python.
I just implemented it into an algo in Python and it was disappointing.
I did the same test for it with 5000 paths first changing the game_map before each pathfinding operation and then 5000 paths without changing the map. I uploaded the algo and used it in the playground and looked at the time it needed per round to execute this test. The results are:
15000-22000 ms for 5000 paths (changing the board)
300-400 ms for 5000 paths (without changes)
Of course the algo is now also creating and removing units adding to the time which I ignored in my C# test but this is 5-10 times slower than the C# version.
I literally copied my code line by line translating from C# to Python and I don’t know if it is the server, my missing knowledge of optimisation for Python or both that caused this.
Python is naturally going to be slower, but there are ways to reduce this. The first place I would look is your data structures and loops. If you copied your code line by line from C# to python, I would think you are still using lists. While great, lists are vastly over-used by python programmers who do not understand the benefits and functionality of other data types. Essentially, since everything in python is stored as an object, lists become very expensive if you use them a lot, and loop through them and sublists.
Anywhere you are searching or looping through a list when you could use a dict will be much faster.
I would recommend looking at data structures like dicts and sets which have efficiency O(1) instead of O(n) for searching. It really depends on how you are storing paths and their data. I would also mention that if you are creating a lot of lists that do not change, you might see some minor gains by using tuples instead of lists. They will still have the same speed in searching, sorting, etc but are (usually - this can depend on what the list/tuple contains, special conditions, etc) a little bit faster to create than lists.
Also, in order to really measure this you should run the exact same conditions for each test. By adding/removing units to the map, you are forcing the map to re-calculate (I assume you’re caching the map) it’s values and adding significantly more computations for the python test.
Thanks for this very helpful reply!
I tried the things you suggested and it helped to lower the time significantly.
My new results are:
10000-16000 ms for 5000 paths (changing)
62 ms for 5000 (unchanged)
I replaced every grid that previously used lists within a list, with a dict and replaced every coordinate with a tuple. Changing some double for-loops (for x and y) into a single loop for element in dict.values() propably also helped. While checking the code I also got rid of a little bug that reset every node twice instead of just once when the map changed.
Also to clarify the measuring of the python test:
Adding/removing units and getting a path after that for 5000 iterations was all the algo was doing every turn so I measured the time the algo needed to do a turn without this to get the base-time. After that, I took the time the algo needed to process the base + adding/removing units 5000 times.
The times are 11 ms base-time and 51 ms adding/removing so it doesn’t really affect my test, subtracting 50 ms from 10-16s.
This is so fast because my pathfinding doesn’t recalculate when changing a map. It just resets the nodes (just when needed) and sets a boolean value to False to show that it isn’t initialized. When a path needs to be found, the pathfinding checks the value and initializes the nodes if needed. So it doesn’t do any unnecessary calculations.
Very nice, glad you were able to get some metrics down :). Also thanks for the clarification on how you were measuring times, that was quite helpful.
Lists and loops are always the first place I look for speed improvements, but there are lots of other little things as well that you can continue to look at (probably for less gains). These are specific to Python because dynamically typed languages (like Python) do lots of things to try and “ease” the process of programming.
This is an interesting article for why Python is slow, and goes into quite a bit of depth about the Python under the hood if you are interested (it assumes a bit of prior knowledge): https://jakevdp.github.io/blog/2014/05/09/why-python-is-slow/
 .
.